비동기 서버 제대로 사용하기 - Netty의 성능을 5배 높인 방법
최근 신제품 서버의 하드웨어 스펙을 결정하기 위한 부하 테스트를 진행하던 중, Netty 기반 서버의 성능이 예상을 크게 밑도는 것을 발견했습니다.
참고를 위해 Spring MVC로 구현된 HTTP API의 성능도 함께 측정했는데, 오히려 Netty 기반 TCP 서버가 더 낮은 성능을 보이는 이상 현상이 발견되었습니다. TCP가 HTTP보다 더 가벼운 프로토콜임에도 불구하고 말이죠.
이를 계기로 서버 구현을 전반적으로 재검토하게 되었고, Netty의 이벤트 기반 아키텍처를 제대로 활용하여 의미 있는 성능 개선을 달성할 수 있었습니다.
이 글에서는 성능 개선 과정에서 발견한 문제점과 해결 방법을 단계별로 공유하고자 합니다.
테스트 환경 구성
성능 테스트의 정확성을 위해 모든 구성 요소를 독립된 가상 머신에서 실행했습니다.

인프라 스펙
API Server
Spring Boot 3 / OpenJDK 17
CPU: 1vCPU
Memory: 1.5GB
Database
MySQL 8.0
CPU: 1vCPU
Memory: 2GB
부하 테스트 환경
Locust (Master 1대, Worker 10대)
각 노드: 1vCPU, 1GB Memory
테스트 시나리오
비즈니스 로직
데이터베이스 쿼리 처리 시간을 시뮬레이션하기 위해 20ms의 지연을 발생시키는 간단한 로직을 구현했습니다.
1
2
3
4
5
6
public void simulateDbQuery() {
// 데이터베이스 쿼리 실행 시간을 20ms로 고정
entityManager.createNativeQuery("SELECT SLEEP(0.02)").getSingleResult();
}
부하 테스트 조건
동시 접속자: 1,000명 (50명씩 점진적 증가)
테스트 시간: 5분
Spring Web MVC 성능 측정 (기준점)
성능 개선의 필요성을 판단하기 위해, 먼저 동일한 비즈니스 로직(20ms DB 쿼리)을 처리하는 HTTP API 서버의 성능을 측정했습니다. Spring Web MVC로 구현된 API 서버를 선택했으며, 모든 설정은 기본값입니다.
Note: HTTP API와 TCP 서버는 프로토콜 레벨이 다르기 때문에 직접적인 성능 비교는 적절하지 않습니다. 다만, 동일한 비즈니스 로직을 처리할 때 일반적으로 TCP가 더 가벼운 프로토콜이므로, 이 측정 결과는 Netty TCP 서버의 성능 개선 필요성을 인지하는 참고 지표로 활용했습니다.
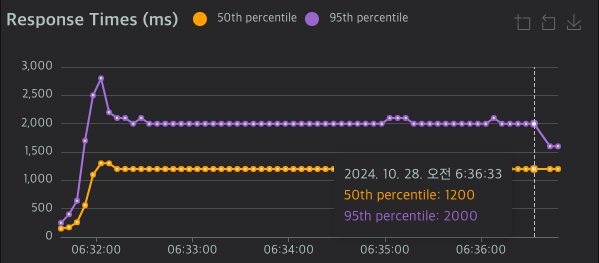
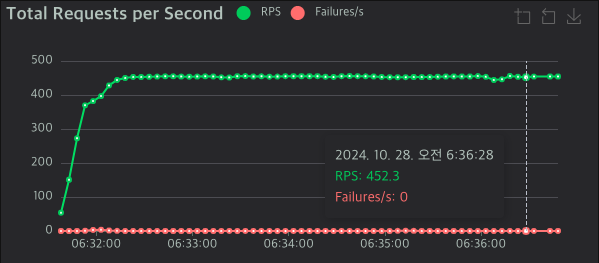
성능 측정 결과
| 측정 지표 | 결과 |
|---|---|
| RPS | 442.75 |
| 응답시간 (50%ile) | 1,200ms |
| 응답시간 (95%ile) | 2,000ms |
결과 분석
20ms의 데이터베이스 쿼리를 처리하는 API임을 고려할 때, 응답 시간이 다소 높게 측정되었습니다. 이는 다음과 같은 환경적 제약에서 기인합니다:
단일 CPU 코어 환경에서 200개의 Tomcat 스레드가 경쟁
스레드 컨텍스트 스위칭 오버헤드 발생
제한된 리소스 환경에서의 스레드 풀 운영
이러한 Spring MVC의 성능 측정 결과를 기준으로 Netty 서버의 성능을 비교 평가하겠습니다.
Netty 아키텍처 간단 소개
Netty는 비동기 이벤트 기반 네트워크 프레임워크입니다. 성능 최적화 과정을 이해하기 위해 핵심 컴포넌트들을 살펴보겠습니다.
주요 컴포넌트
1. Channel
네트워크 연결을 추상화한 핵심 컴포넌트입니다.
- 소켓 수준의 I/O 작업 추상화
- 모든 I/O 작업은 비동기로 동작하며 ChannelFuture 반환
- 데이터 읽기(인바운드)와 쓰기(아웃바운드) 담당
2. EventLoop
단일 스레드로 동작하는 이벤트 처리 엔진입니다.
- 네트워크 이벤트(연결, 읽기, 쓰기) 처리
- 하나의 Channel은 하나의 EventLoop에 고정 할당
- 여러 Channel이 하나의 EventLoop 공유 가능
3. EventLoopGroup
EventLoop들을 관리하는 스레드 그룹으로, 서버에서는 두 종류의 그룹을 사용합니다:
- bossGroup: 클라이언트 연결 수락만 담당 (보통 1개 스레드)
- workerGroup: 실제 데이터 처리 담당 (기본값: CPU 코어 수 * 2)
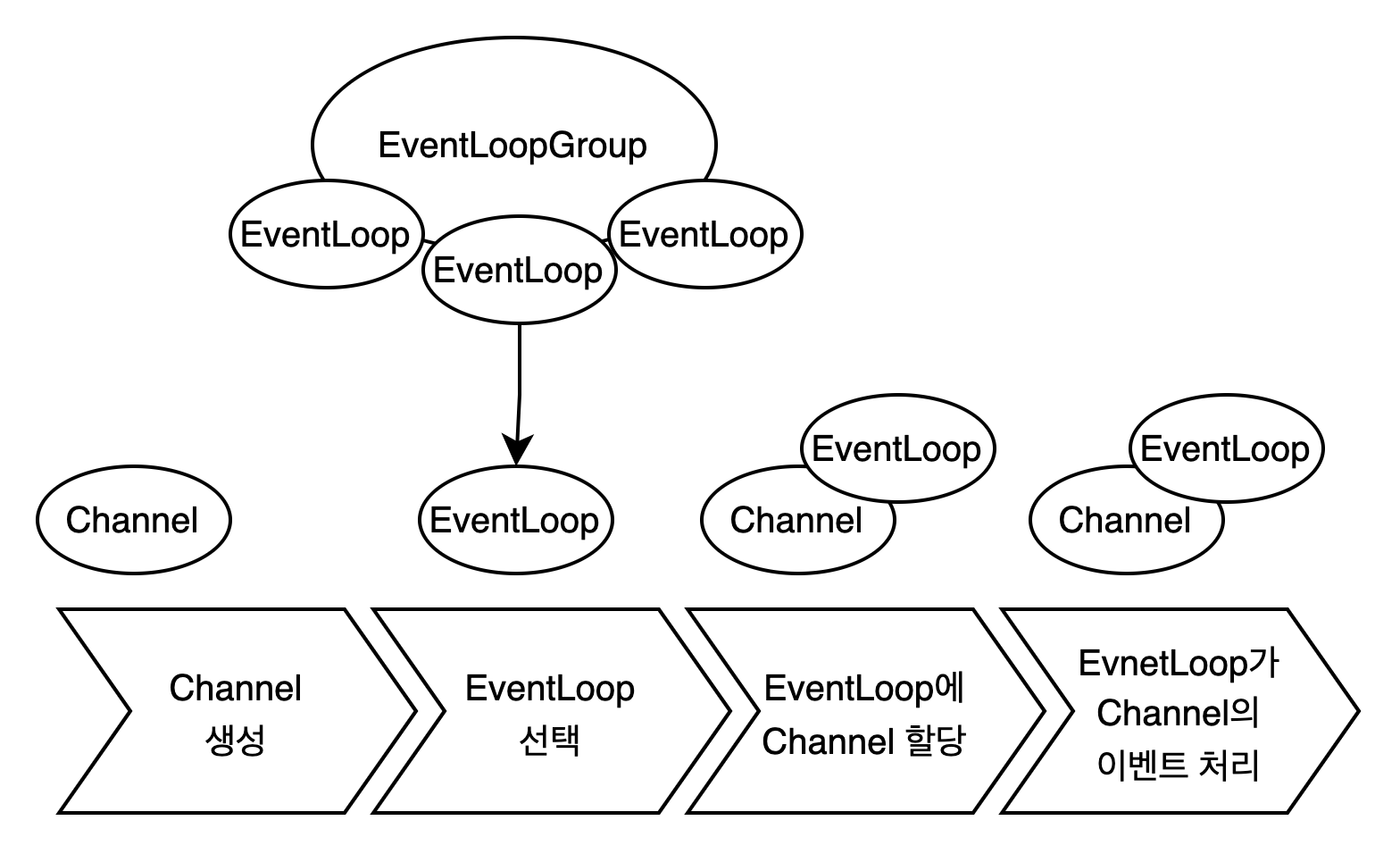
이벤트 기반 처리 방식
이벤트 루프 메커니즘
각 EventLoop는 자신만의 이벤트 큐를 가지고 있어 다음과 같이 동작합니다:
- 이벤트 발생 감지 (연결, 데이터 수신 등)
- 이벤트를 큐에 등록
- 순차적으로 이벤트 처리
- 처리 완료 후 다음 이벤트 대기
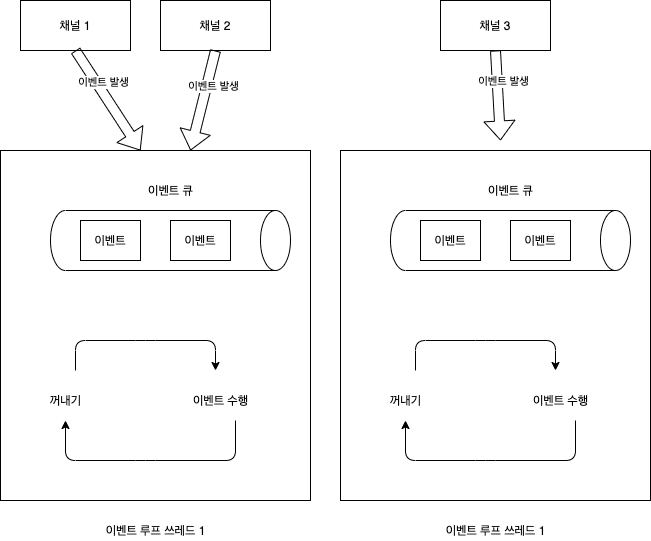
ServerBootstrap으로 서버 구성하기
Netty 서버를 실제로 구성하고 실행하기 위해서는 ServerBootstrap 클래스를 사용합니다. 이 클래스는 서버의 주요 설정을 담당합니다.
주요 설정 항목
- EventLoopGroup 설정
- bossGroup: 클라이언트 연결 수락 전용
- workerGroup: 데이터 처리 전용
- Channel 설정
- NioServerSocketChannel: 비동기 I/O 모드
- ChannelPipeline 설정
- 데이터 처리 로직 정의
- 인코더/디코더 및 비즈니스 로직 핸들러 등록
서버 구성 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class NettyServer {
public void start() {
// EventLoopGroup 생성
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap bootstrap = new ServerBootstrap()
// EventLoop 그룹 설정
.group(bossGroup, workerGroup)
// 비동기 I/O 모드 사용
.channel(NioServerSocketChannel.class)
// 데이터 처리 파이프라인 설정
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline()
.addLast(new DatabaseQueryHandler()); // 20ms 소요되는 DB 쿼리
}
});
// 서버 시작
ChannelFuture future = bootstrap.bind(8080).sync();
// 서버 종료 대기
future.channel().closeFuture().sync();
} finally {
// 자원 정리
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
}
주요 특징
비동기 처리: 블로킹 없는 I/O 작업으로 리소스 효율성 극대화
이벤트 기반: 이벤트 루프를 통한 효율적인 이벤트 처리
스레드 최적화: 최소한의 스레드로 다수의 연결 처리
확장성: CPU 바운드 작업과 I/O 바운드 작업 분리 가능
이러한 아키텍처를 기반으로, 다음 섹션에서는 실제 성능 테스트 결과와 최적화 과정을 살펴보겠습니다.
Netty 서버 1차 테스트 - 기본 설정의 한계
먼저 Netty 서버를 기본 설정으로 구성하여 성능 테스트를 진행했습니다. 결과는 예상과 달리 매우 저조했습니다.
성능 측정 결과
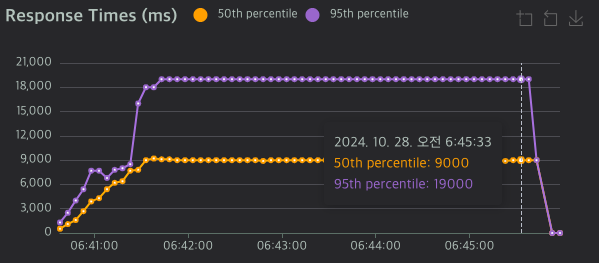
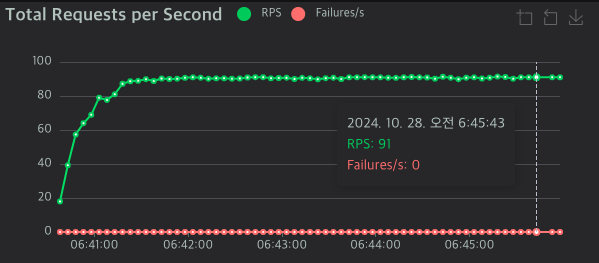
| 서버 유형 | RPS | 응답시간 50%ile | 응답시간 95%ile |
|---|---|---|---|
| Spring MVC | 442.75 | 1,200ms | 2,000ms |
| Netty 1차 | 91 | 9,000ms | 19,000ms |
Spring MVC와 비교했을 때 Netty 서버의 성능이 현저히 떨어졌습니다. RPS는 5배 이상 낮았고, 응답 시간은 무려 7배 이상 높게 나왔습니다. 전체 요청의 절반 이상이 9초가 넘는 응답 시간을 보였습니다.
왜 이렇게 느린걸까?
문제의 원인을 찾기 위해 서버 구성 코드를 살펴보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class NettyServer {
public void start() {
// 기본 설정으로 EventLoopGroup 생성
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline()
.addLast(new DatabaseQueryHandler()); // 20ms 소요되는 DB 쿼리
}
});
serverBootstrap.bind(serverPort).sync();
}
}
가장 먼저 눈에 띄는 것은 NioEventLoopGroup의 생성 부분입니다. 스레드 수를 지정하지 않고 기본값을 사용했는데요, Netty는 이런 경우 다음과 같은 계산식으로 스레드 수를 결정합니다:
1
2
3
4
5
private static final int DEFAULT_EVENT_LOOP_THREADS =
Math.max(1, SystemPropertyUtil.getInt(
"io.netty.eventLoopThreads",
NettyRuntime.availableProcessors() * 2
));
우리의 테스트 환경은 CPU가 1코어입니다. 따라서 위 계산식에 의해 workerGroup에는 단 2개의 EventLoop만 생성됩니다. 이 2개의 EventLoop가 1,000개의 동시 연결을 처리해야 하는 상황이 된것입니다.
여기서 더 큰 문제는 각 요청이 수행하는 DB 쿼리입니다. JDBC 드라이버를 사용한 DB 쿼리는 블로킹 작업이라서, 쿼리가 완료될 때까지 EventLoop 스레드를 점유합니다. 각 쿼리는 20ms가 소요되는데, 하나의 EventLoop가 500개의 연결을 순차적으로 처리해야 합니다. 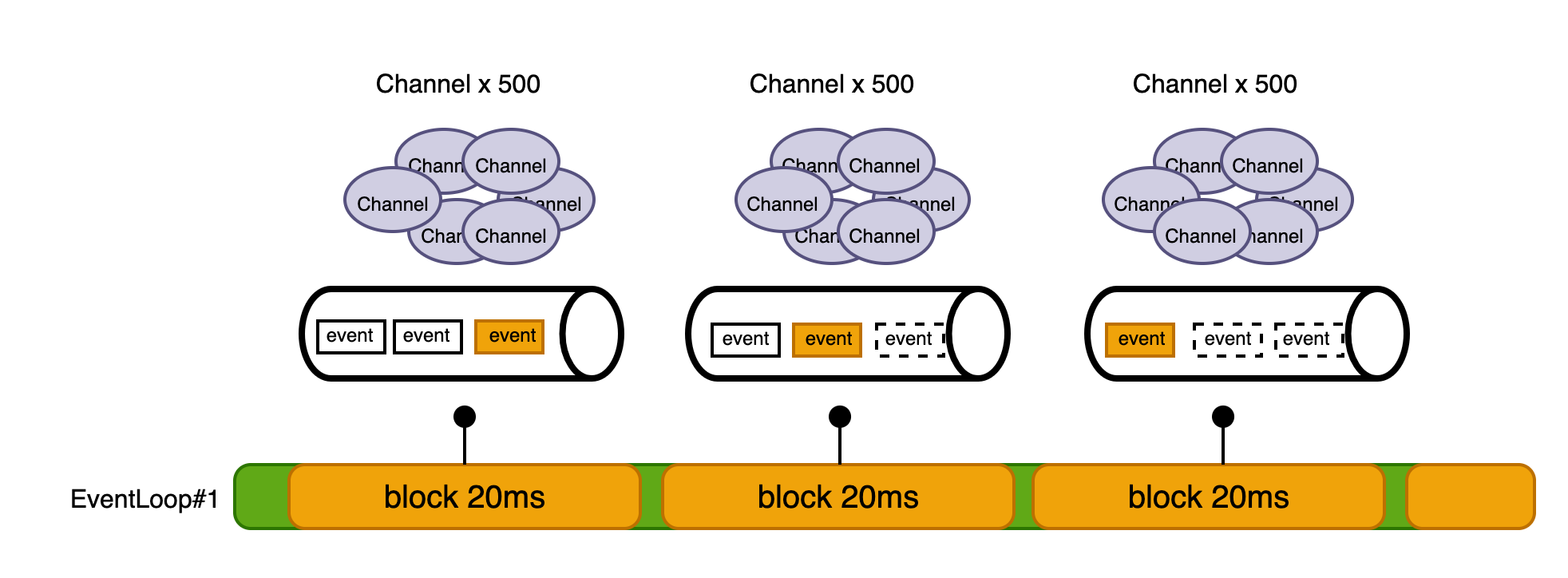
결과적으로 다음과 같은 병목 현상이 발생합니다:
- EventLoop가 하나의 요청을 처리하는 동안(20ms) 블로킹
- 이벤트 큐에 대기 중인 나머지 499개 요청은 처리되지 못하고 대기
- 대기 시간이 누적되면서 전체적인 응답 시간 증가
- 결과적으로 RPS 저하
이러한 문제를 해결하기 위해, EventLoop 설정을 변경하여 2차 테스트를 진행했습니다.
Netty 서버 2차 테스트 - EventLoop 스레드 증가
Note: 이번 테스트는 임시방편적인 해결책입니다. 최적화 과정의 시행착오로 봐주시면 감사하겠습니다.
앞서 발견한 문제를 해결하기 위한 첫 시도로, EventLoop의 수를 2개에서 10개로 증가시켜 테스트를 진행했습니다.
1
2
3
4
5
6
7
8
9
10
11
public class NettyServer {
public void start() {
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
// EventLoop 스레드 수를 10개로 증가
EventLoopGroup workerGroup = new NioEventLoopGroup(10);
ServerBootstrap serverBootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
// ... 나머지 설정 동일
}
}
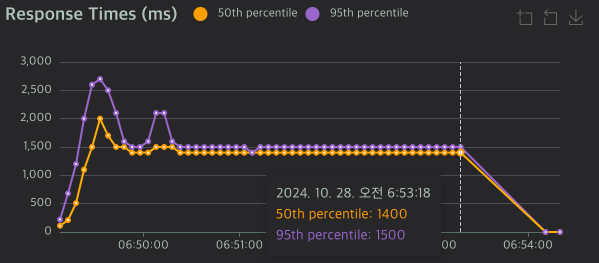
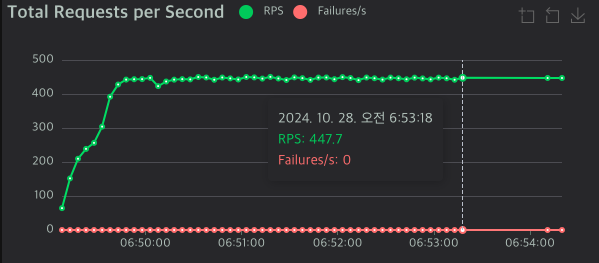
성능 측정 결과
| 서버 유형 | RPS | 응답시간 50%ile | 응답시간 95%ile |
|---|---|---|---|
| Spring MVC | 442.75 | 1,200ms | 2,000ms |
| Netty 1차 | 91 | 9,000ms | 19,000ms |
| Netty 2차 | 425.03 | 1,400ms | 1,600ms |
개선점과 한계
EventLoop 스레드 수를 늘린 결과, Spring MVC와 비슷한 수준의 성능을 달성할 수 있었습니다. 구체적으로:
- RPS가 91에서 425로 크게 향상
- 응답 시간이 9초에서 1.4초로 대폭 감소
- 전반적인 성능이 Spring MVC와 유사한 수준으로 개선
하지만 이는 근본적인 해결책이라고 보기 어렵습니다. 여전히 다음과 같은 문제가 존재하기 때문입니다:
- EventLoop가 여전히 블로킹 작업을 직접 처리
- DB 쿼리 실행 중에는 해당 EventLoop가 블로킹
- Netty의 비동기 이벤트 기반 모델의 장점을 제대로 활용하지 못함
다음 섹션에서는 블로킹 작업을 EventLoop에서 분리하여 진정한 의미의 비동기 처리를 구현해보겠습니다.
Netty 서버 3차 테스트 - 블로킹 작업 분리
앞선 테스트에서 단순히 EventLoop 스레드 수를 늘리는 것은 임시방편에 불과했습니다. 이번에는 보다 근본적인 해결책으로, 블로킹 작업을 별도의 스레드 풀로 분리해보겠습니다.
EventExecutorGroup 도입
Netty는 블로킹 작업을 위한 전용 스레드 풀로 EventExecutorGroup을 제공합니다. 이를 통해 I/O 처리와 비즈니스 로직을 명확히 분리할 수 있습니다.
- EventLoop: 순수하게 네트워크 I/O 이벤트 처리
- EventExecutorGroup: DB 쿼리 등 블로킹 작업 처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class NettyServer {
public void start() {
// I/O 이벤트 처리용 EventLoop
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup(2);
// 블로킹 작업 처리용 스레드 풀
EventExecutorGroup blockingTaskGroup = new DefaultEventExecutorGroup(10);
ServerBootstrap serverBootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline()
// 블로킹 작업은 별도 스레드 풀에서 처리
.addLast(blockingTaskGroup, new DatabaseQueryHandler());
}
});
// ... 서버 시작 코드 ...
}
}
이렇게 구성하면:
- EventLoop (2개)
- 클라이언트 연결 및 I/O 이벤트 처리
- 블로킹 작업이 없어 지연 없이 처리 가능
- EventExecutorGroup (10개)
- DB 쿼리 등 블로킹 작업 전담
- 작업 완료 후 결과를 EventLoop에 반환
이러한 구조로 인해 EventLoop는 블로킹 없이 빠르게 I/O를 처리할 수 있고, 블로킹 작업은 별도의 스레드 풀에서 안전하게 처리됩니다.
성능 측정 결과
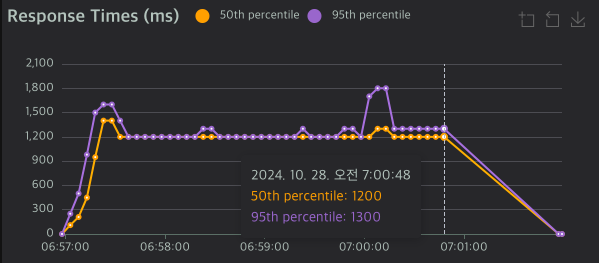
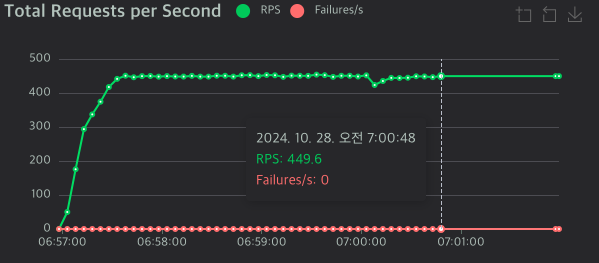
| 서버 유형 | RPS | 응답시간 50%ile | 응답시간 95%ile |
|---|---|---|---|
| Spring MVC | 442.75 | 1,200ms | 2,000ms |
| Netty 1차 | 91 | 9,000ms | 19,000ms |
| Netty 2차 | 425.03 | 1,400ms | 1,600ms |
| Netty 3차 | 449.60 | 1,200ms | 1,300ms |
개선 효과 분석
이번 접근 방식으로 놀라운 성능 향상을 달성했습니다:
- 극적인 성능 개선 (1차 테스트 대비)
- RPS가 91에서 449로 약 5배 향상
- 응답 시간이 9,000ms에서 1,200ms로 87% 감소
- 95%ile 응답 시간이 19,000ms에서 1,300ms로 93% 감소
- Spring MVC 대비 우수한 성능
- 더 높은 RPS (449 vs 442)
- 동등한 평균 응답 시간 (1,200ms)
- 더 나은 95%ile 응답 시간 (1,300ms vs 2,000ms)
- 리소스 활용 최적화
- EventLoop는 I/O 처리에 집중
- 블로킹 작업은 전용 스레드 풀에서 처리
- 시스템 자원의 효율적 분배
이제 Netty 서버가 본연의 강점을 제대로 발휘할 수 있게 되었습니다. EventLoop는 빠른 I/O 처리에 집중하고, 블로킹 작업은 별도의 스레드 풀에서 처리함으로써 전체적인 시스템 성능이 크게 향상되었습니다.
결론: Netty 서버 성능 최적화의 핵심 교훈
세 차례의 성능 테스트와 최적화 과정을 통해 얻은 핵심 교훈을 정리해보겠습니다.
1. EventLoop의 역할과 중요성
- EventLoop는 네트워크 I/O 처리를 위한 특수한 목적의 스레드
- 블로킹 작업이 발생하면 전체 시스템 성능이 크게 저하
- 단일 스레드로도 수백 개의 연결을 효율적으로 처리 가능
2. 블로킹 작업의 적절한 처리
- JDBC 쿼리와 같은 블로킹 작업은 반드시 분리
- EventExecutorGroup을 통한 작업 위임
- 비즈니스 로직과 I/O 처리의 명확한 분리
3. 효율적인 리소스 관리
- 단순한 스레드 증가는 근본적인 해결책이 될 수 없음
- 작업 특성에 따른 적절한 스레드 풀 구성
- 최소한의 리소스로 최대한의 성능 달성
최종 성과
- TCP 프로토콜의 장점을 살린 성능 달성
- 응답 시간의 일관성 확보 (95%ile 응답시간 35% 개선)
- 시스템 리소스의 효율적 활용
이번 최적화 과정을 통해 단순히 성능 개선을 넘어, Netty의 진정한 강점을 이해하게 되었습니다. “비동기 프레임워크를 동기식으로 사용하면 오히려 성능이 저하될 수 있다”는 교훈을 얻었고, 이는 다른 비동기 프레임워크 사용 시에도 적용될 수 있는 중요한 원칙이 될 것입니다.