인덱스 손익분기점
DDB 테이블에 저장된 데이터를 읽는 방식은 두 가지가 있습니다.
- Table Full Scan - 테이블 전체를 스캔해서 읽기
- Index Range Scan - 인덱스를 이용한 테이블 액세스
인덱스 활용이 가능한 쿼리 임에도 불구하고 Table Full Scan을 사용하겠다는 쿼리 실행계획을 종종 보곤 합니다. DBMS에서 인덱스 활용이 조회 성능을 더 악화시킨다고 판단한 것입니다.
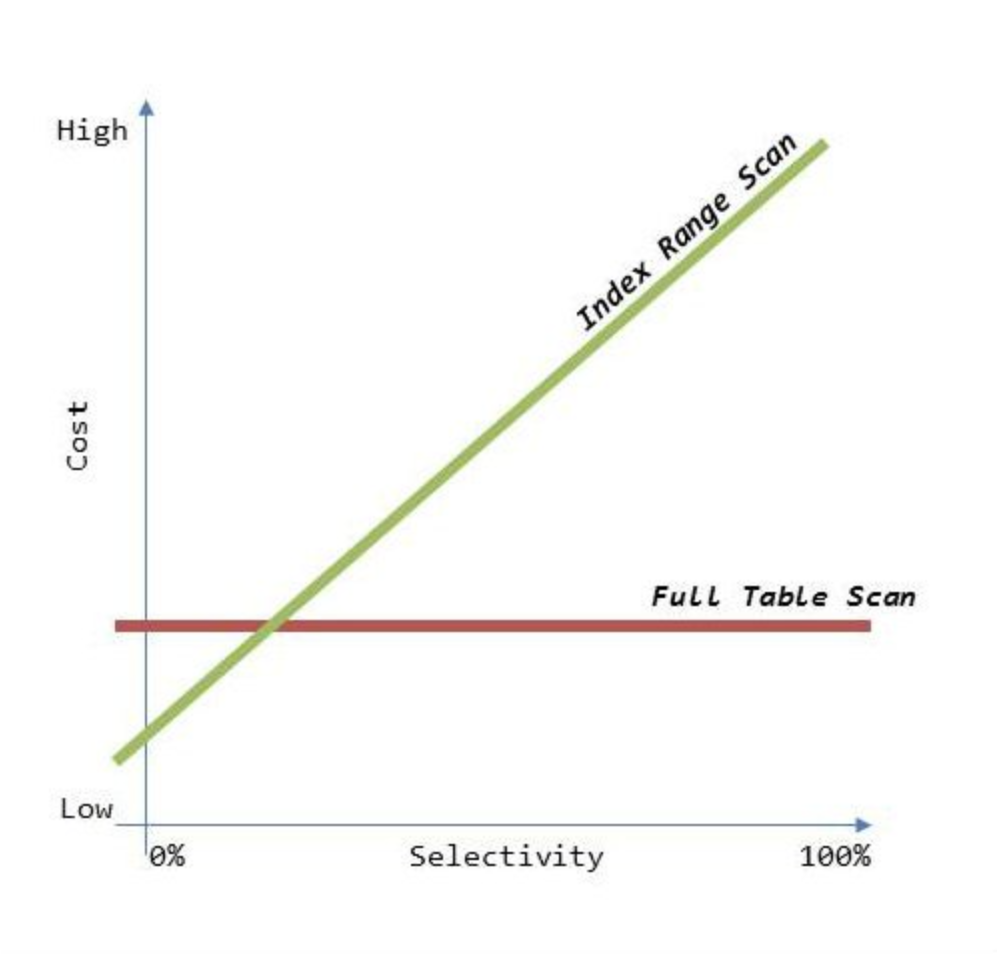
어떤 경우에, 왜 Index Range Scan의 성능이 Table Full Scan의 성능보다 떨어지는지 알아보았습니다!
그 전에, 왜 알아봐야 할까?
- 요구사항에 적합한 DB 스키마 / 쿼리를 설계 하려면 알고 있어야 하는 핵심 개념이기 때문이다.
- 인덱스는 공짜가 아니다. 조회 성능은 좋아지지만 반대로 insert, delete, update 성능은 떨어진다.
어떤 경우에 성능이 떨어질까?
- 쿼리를 통해 추출 하려는 레코드 건수가 많아질수록 Index Range Scan의 성능은 떨어집니다.
- 보통 테이블 전체 데이터 중 5~20% selectivity 수준에서 손익분기점이 결정됩니다.
- 전체 데이터의 갯수가 많아질수록 손익분기점은 더 낮아질 확률이 높아집니다.
- 버퍼 캐시 히트율이 떨어질 확률이 크기 때문입니다.
- CF(clustering Factor) 비율이 떨어질 확률이 크기 때문입니다.
- 1천만건 정도 테이블에서 선택도가 1만건이 넘어가면 Table Full Scan으로 읽는게 더 빠를 수 있습니다.
- Table Full Scan은 선택도와 상관 없이 성능이 거의 일정합니다.
왜 성능이 떨어질까?
| 항목 | Table Full Scan | Index Range Scan |
|---|---|---|
| 액세스 방식 | 시퀀셜 액세스 | 랜덤 액세스 |
| I/O 방식 | Multi Block I/O | ROWID를 이용한 Single Block I/O |
SQL 성능 저하가 발생하는 이유는 대부분 디스크 I/O 때문입니다. DBMS 프로세스는 디스크에서 데이터를 읽어야 할 땐 OS 함수를 호출하고 CPU반환 및 wait 상태가 됩니다.
OS가 데이터를 반환할 때까지 DBMS 프로세스가 일을 멈추는 것입니다. 여기서 DB 조회 병목이 발생하게 됩니다.
다시말해 디스크 I/O 횟수가 많아질수록 조회 쿼리 성능은 떨어지게 됩니다.
그런데 Index Range Scan이 사용하는 랜덤 액세스, Single Block I/O 방식은 데이터 선택도가 높아질수록 Table Full Scan 방식보다 상대적으로 디스크 I/O 횟수가 더 많이 증가하게 됩니다.
때문에 선택도가 어느 수준 이상이 되면 Index Range Scan의 디스크 I/O 횟수가 Table Full Scan보다 더 많아지게 되고 성능 역전이 발생하게 되는 것입니다.
[!TODO] 왜 성능이 떨어지는지 정확히 알려면 먼저 아래 항목에 대해 이해하고 있어야 함
- 데이터베이스 저장 구조
- 버퍼 캐시 탐색 메커니즘
- 랜덤 I/O, 시퀀셜 I/O
- 인덱스 수직 / 수평 탐색
- 인덱스 ROWID를 이용한 테이블 탐색 메커니즘
- 인덱스 클러스터링 팩터
- Multi Block I/O & Single Block I/O
결론
- 인덱스는 소량의 데이터를 읽을 때 성능 혜택을 누릴 수 있습니다.
- Table Full Scan이 항상 나쁜 것은 아니며, 인덱스 스캔이 항상 좋은 것도 아닙니다.
- 무작정 인덱스를 맹신 하는것이 아닌 요구 사항에 적합한 스키마 설계 / 쿼리 튜닝을 해야 되겠습니다.
ps.
SQL 튜닝은 램덤 I/O와의 전쟁이다. SQL 성능 향상을 위해 DBMS가 제공하는 많은 기능이 느린 랜덤 I/O를 극복하기 위해 개발됐고, 조인 메소드의 발전은 물론 많은 튜닝 기법도 랜덤 I/O 최소화에 맞춰져 있다. -친절한 SQL 튜닝 129p